資料分析
 將架構界定好,接著寫程式、使用分析工具執行
將架構界定好,接著寫程式、使用分析工具執行
通常分析前我會先想一個初步的架構,否則要看的變數太多了會很容易迷失,這一次我們的架構如下:
- 填答者輪廓
- 職業對滿意度的差異分析
- 教育對滿意度的差異分析
- 象限分群,了解不同使用族群的問題點
- 網站功能優化策略
下載下來的資料在Excel中打開大概長這樣:

但是中文對於程式操作上很不方便,因為語法大部分都是英文的,所以我會自己再另外設計一下變數名稱, 如果不設計的話變數會顯得很雜亂、名稱太長,這些都不是好的變數。雜亂是什麼意思呢?比方說這份問卷的後面問題都在問滿意度相關的,那其實可以在這些變數前面透過一個類別名稱去命名它,比如nps_{問的問題}的格式去重新命名 (凈推薦值,雖然這邊用里克特量表,自己看得懂就好)
 整理成英文命名,並群組化變數
整理成英文命名,並群組化變數
剛開始我會優先觀察「人口特徵」的資料,了解填答者的輪廓。通常依照問卷投放的渠道會有不同的填答者。又剛好這次使用的資料投放管道主要為網站使用者填寫,也就是說它正面反應了網站使用者的輪廓。

主要報稅人以30~59為主,這群人也是稅務網站主要服務的對象。而大多數人都是使用PC來處理報稅流程,這點與我們的認知相同。並且推測都是下班後處理,在晚上來操作網站。
女性比較多一些,另外大部分人其實不是新竹的居民。

在大學的統計學第一節課程中會告訴我們資料有四種尺度,而其中問卷調查常常出現的滿意度屬於ordernal data(順序資料,資料間沒有運算關係,但有順序關係,比如5 > 4 是「程度上的差別」,但是不會說「5比4高1滿意度」),我會透過小提琴圖來觀察滿意度的分佈,好處是你可以看到不同類別(這邊用職業,你也可以用年齡區間、教育程度等等個體間的差異)在5個分數上的分佈情況,藉此一眼就掌握個體間對於滿意度的差異,可以回答兩個問題:
- 「什麼樣的個體比較滿意什麼環節」
- 「個體A在B的集中情況,是否有極端值?」
而一口氣觀察這些變數的分布也很簡單,三行左右,此時先前重新命名變數的好處就體現出來了,我可以用一點語法就找到所有我想觀察的變數(比如說名稱中有nps的欄位)然後寫個迴圈把所有圖一次性畫出來:

有趣的是在滿意度調查中,農林漁牧業人員的分佈與其他職業比較不同,這點如果回到資料筆數去看,就知道是因為資料筆數比較少的關係,從理論上,當資料筆數愈多,則各個分數區間都會是常態的,無須太過緊張。
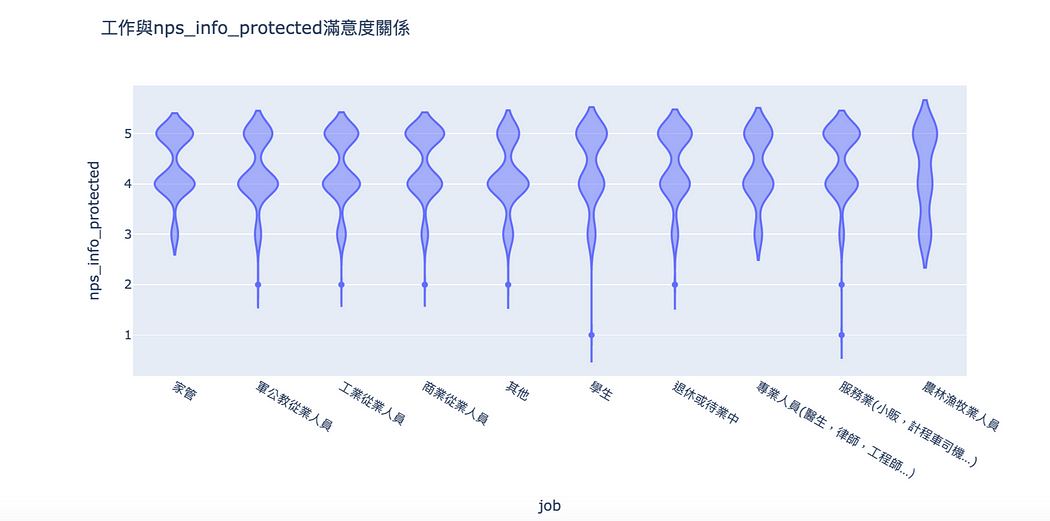
另外可以觀察到大部分人給出的滿意度都偏高,尤其是服務業、商業從業人員給予滿分的評價較多。

/政府網站營運交流平台授權轉載/
原文作者:戴士翔 | Dennis Dai
原文出處medium:開放資料優化使用者體驗,以臺灣政府稅務資料為例