改善流程藏在哪處?

將各個流程梳理清楚
我們來看看平均而言,哪個環節比較需要改善:可以看到雖然數值的差距不明顯,但是透過折線圖就可以發現:
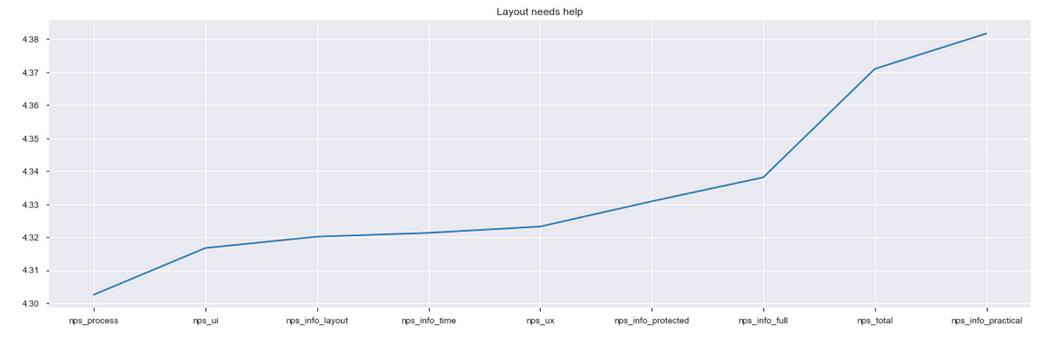
折線圖是觀察差異最好的視覺化工具
這裡可以發現有三處明顯的拐點,作為管理者可以思考手上的資源可以改善的範圍,比方說如果資源比較少、預算較緊,那麼就優化第一個拐點(流程),如果這是一個專案,則從資訊完整度以下都可以安排優化(info_full)
- 實用性部分分數最高,表示消費者還是認可這個產品的價值,換句話說要優化「實用」部分,創新點就是「有沒有其他媒體」、「其他表達形式」來更好傳遞價值?
- 清楚看到需要改善的是流程,再到UI、Layout,UI跟Layout其實如出一徹,都是視覺方面需要改善的訊息,不夠美觀大方,排版也沒那麼好搜尋。
- 即時更新的部分比較差強人意,操作便利性上還過得去。
 政府的報稅網站
政府的報稅網站
但是流程真的這麼差嗎?我們可以細看它的職業差異分佈:
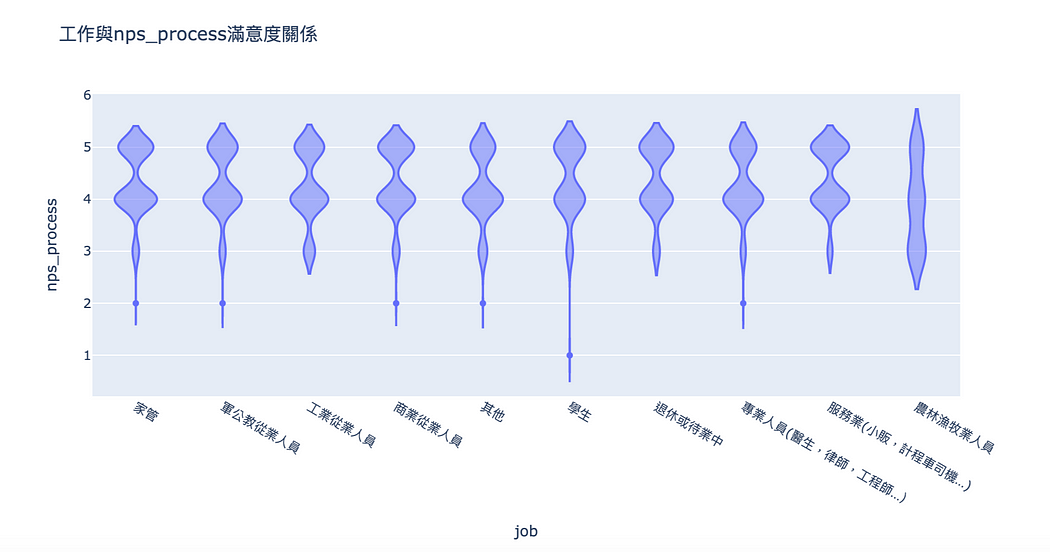
nps_process其實蠻有趣的,只有學生有給到1分的評價,這點可能是因為學生報稅經驗比較不足,所以對流程的掌握度比較差,而退休人員則是對process的部分滿意度偏高,這可能也是因為他們是最熟悉、有最多報稅經驗的人,所以對這方面比較無感。

在info_time則看到幾乎每個職業的人都給到了2分以下,這在其他環節是沒有看到的現象,畢竟觀察其他小提琴圖會知道頂多專業人員、軍公教人員比較嚴格、給予比較低的評價,但是少見所有職業都給出低分的選項,由此可知我們在time的部分(即時更新)上需要做到調整,因為雖然overall並不是最低分,但是這一塊是幾乎所有職業都有不滿意族群存在的部分,這部分我們就要進一步了解問題、思考可以怎麼改善。
PCA 主成份分析
我們可以用主成份分析來把資料降維,這邊我把滿意度指標投影到二維平面上,透過資料投影與類別的組合往往可以發現一些不錯的模式,是一個很常見的機器學習技巧。
PCA解釋了約79%的變異,效果還不錯

接著我們解讀PCA的組成因子,可以看到:
- 第一個主成分主要由資訊(info)相關組成,比如說實用度、更新即時性、資料保護程度(nps_info_practical、nps_info_time)
- 第二個主成份主要由使用者體驗、介面操作(nps_ui,nps_ux)為主。
 非常雜亂,也有可能是2D不足以說明他們之間的模式
非常雜亂,也有可能是2D不足以說明他們之間的模式
然而似乎沒有什麼特別的模式,各職業的滿意度並沒什麼差別。
如何解決雜論無章的問題?象限分群
那我們可以怎麼樣獲得更深刻的洞察呢?就是利用「象限法」也就是透過將散點圖透過中間值來去區分四個象限的資料,並且為他們加上人物側寫(取每個集群的最大數)。象限法很簡單卻很好用,搭配散點圖可以劃分出不同資料個體間的關係,進而做出簡單的四個群體。
比如管理學中著名的BCG矩陣就是將成長率、市占率為軸所畫分出來的產品組合理論,這理論背後最為重要的其實是「選軸、區分象限」的思想,而這也是我們可以借鑑到不同數據分析專案中的:
 印出每一群體的主要特徵代表「群集個體」
印出每一群體的主要特徵代表「群集個體」
不同象限的人物輪廓如圖,這樣的結果其實不錯,我們可以看到結果十分類似,更加確立了平台的使用者輪廓,比如我可以這樣描述這群使用者:
40–49歲、大學專科學歷畢業的女性工、商業從業人員,主要都在晚上使用桌上型電腦查詢活動資訊,使用頻率可以分為三個月一次(一季)、一個月內使用不等…最主要的差異體現在:「瀏覽次數」上,那麼我們就可以進一步討論「瀏覽次數差異的主因」
這樣的輪廓還可以讓我們做一些猜想,結合稅務人員來思考這群人的特徵,比如:可能是一個家庭的母親、有正在讀國中的孩子、不想花太多時間填寫網站資料、經常需要查詢活動資訊等等…
/政府網站營運交流平台授權轉載/
原文作者:戴士翔 | Dennis Dai
原文出處medium:開放資料優化使用者體驗,以臺灣政府稅務資料為例